Wikidata and Correspondence Archives
Enriching basic metadata with a knowledge graph
I hope this has shown how Wikidata can add some value as both a way to populate a sparse correspondence dataset with basic metadata, and a way to construct complex queries to highlight groups of individuals in that data. It’s important to note that Wikidata does not claim to store facts in itself: at its core, Wikidata aims to be a repository for knowledge from elsewhere - rather than storing the birth date of Henry Oldenburg, Wikidata hopes to store the fact that, say, the Oxford Dictionary of National Biography records his birth year as 1619 (this is an ideal scenario, whereas in reality much of the information currently comes from Wikipedia).
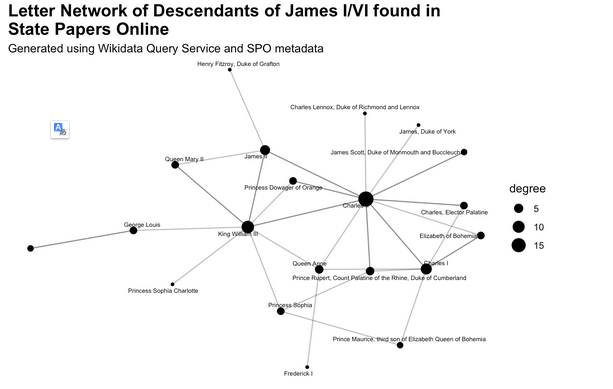
This subtle difference is important, because it means that Wikidata is only as good as the references which make it up. Is it ultimately any use for scholarly work? As we’ve seen, only a small fraction (4,500 out of 30,000) of individuals in the State Papers have been linked to a Wikipedia page, so this can only, at the moment, give us additional metadata on relatively prominent individuals.
However, one can easily see how this same data structure could be used to store much richer information about individuals, and build interesting and complex queries. Connecting this knowledge graph directly to the State Papers metadata, with letters added as entities and properties such as ‘written by’ and ‘language’ would make it much more useful - one could, for example, directly query a knowledge graph and ask for ‘all letters written in French, sent by a relative of a monarch,’ or, ‘all letters written by descendants of Louis XIV